Appian 26.03 accelera su IA, automazione e data fabric: una release che rende piattaforma, processi e sviluppo più flessibili.
Vediamo in questo articolo le novità più importanti di questa una nuova iterazione del Appian che come annunciato passa ad una nuova numerazione, ma al di là del nome, le funzionalità maggiormente evolute sono ancora Process HQ, IA e datafabric.
Intelligenza Artificiale
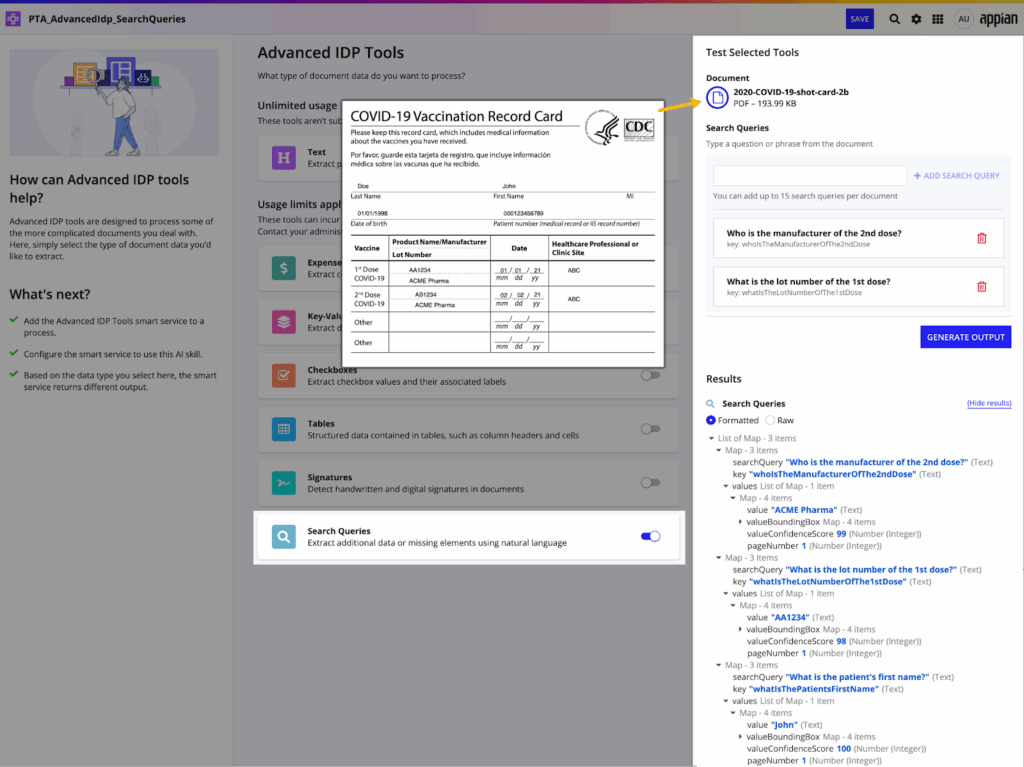
Le funzionalità di IA generativa si ampliano con l’“extended thinking”, che permette ai modelli di affrontare ragionamenti complessi prima di rispondere. L’AI Doc Center fa un ulteriore passo avanti: ora riconosce automaticamente i confini tra documenti all’interno di un unico PDF e li divide in modo intelligente.
In questa versione arriva anche la collaborazione diretta: gli agenti IA modulari possono lavorare insieme per risolvere problemi complessi, senza dover essere inseriti in un unico modello di processo.
Appian Composer
L’Appian Composer permette di caricare più file insieme così l’IA può avere fin da subito una visione completa del progetto e lavorare incrociando le informazioni tra tutti i file caricati, permettendo di ottenere una “story map” (che diventano nativamente esportarbili in formato CSV) e un piano applicativo decisamente più fedeli alle necessità.
Il Co‑Pilot, ora più attivo che mai, non si limita più a suggerire: può intervenire direttamente sugli artefatti dell’applicazione. Puoi chiedergli di aggiungere una tabella al modello dati, modificare i passaggi di un workflow o aggiornare elementi del progetto, e lui esegue le modifiche in autonomia.
Process HQ e Analisi dei Dati
Gli Insight Automatici evolvono: Process HQ ora analizza i KPI in autonomia e mette in evidenza le possibili cause dei rallentamenti. Arriva poi un nuovo modo di visualizzare i dati: i grafici Heat Map.
Da questa versione è possibile creare report e dashboard direttamente da Appian Designer, con in più il supporto al versionamento degli oggetti: questo permette poter confrontare versioni diverse o ripristinare una precedente. Pertanto gli sviluppatori potranno distribuire i report nei loro pacchetti software.
Data Fabric
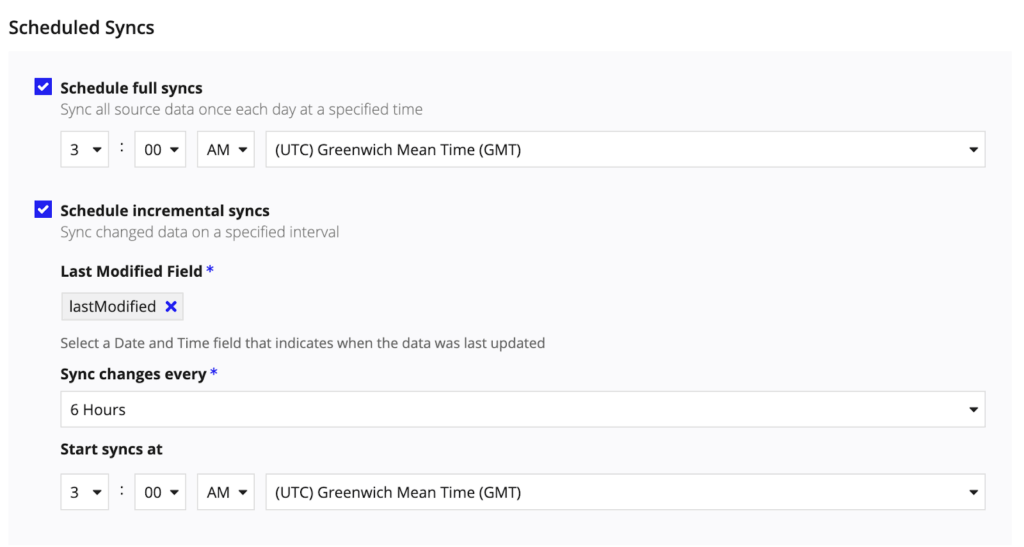
In questa versione non ci sono più le restrizioni sul numero di righe dei record sincronizzati (che abbiamo visto in 25.01) e puoi aggiungere tutte le relazioni che vuoi a un tipo di Record. Questo rende la modellazione dei dati molto più flessibile, soprattutto nei progetti complessi.
Viene introdotto il Direct Data Access ovvero la possibilità di utilizzare le nuove funzionalità di Data Fabric anche per i record non sincronizzati.
In particolare quando si utilizza l’opzione “Direct Data Access” per tipi di record non sincronizzati (in particolare per MariaDB o MySQL), sono disponibili le seguenti funzionalità avanzate:
- Sicurezza e Relazioni avanzate: Anche se i dati rimangono nel database esterno e non vengono sincronizzati, è possibile applicare la sicurezza a livello di record e creare relazioni con altri tipi di record, siano essi sincronizzati o meno.
- Query Federate: Appian è ora in grado di eseguire query che “uniscono” dati provenienti da sorgenti diverse. Ad esempio, puoi mettere in relazione un record sincronizzato con uno non sincronizzato, oppure interrogare contemporaneamente due database esterni diversi.
- Campi Record Personalizzati: Puoi creare e utilizzare campi record personalizzati in tempo reale (custom record fields) anche su questi dati non sincronizzati, permettendo di fare calcoli o trasformazioni al volo senza spostare i dati.
Tutto ciò con la promessa di massima flessibilità di Sviluppo: si potrà passare dal metodo di accesso diretto alla sincronizzazione (e viceversa) man mano che le esigenze dell’applicazione cambiano.
Un’altra novità importante è l’Integrazione con Documentali Esterni. Ora puoi collegare sistemi di gestione documentale come SharePoint direttamente al Data Fabric, accedendo ai file dalle interfacce Appian senza doverli migrare.
Infine, arriva la Ricerca Semantica, alimentata dall’IA: invece di basarsi solo sui nomi o sulle proprietà tecniche, il sistema comprende il significato delle informazioni e ti aiuta a trovare rapidamente i tipi di record più rilevanti. Una ricerca molto più intuitiva, soprattutto quando il modello dati cresce.
Esperienza Utente
La Personalizzazione del Branding fa un salto in avanti grazie ai nuovi profili CSS: ora colori, font e stili possono essere gestiti in modo centralizzato, così ogni applicazione può riflettere perfettamente l’identità visiva dell’azienda senza interventi sparsi o incoerenti.
Sul fronte dell’interfaccia arrivano diversi Nuovi Componenti che ampliano le possibilità di design: il layout a schede per organizzare meglio i contenuti, i toggle e le checkbox booleane per interazioni più chiare, e persino la possibilità di annidare layout side‑by‑side per costruire strutture più articolate e flessibili.
Infine, il Versionamento di Siti e Portali introduce un controllo molto più fine sul ciclo di vita delle interfacce: puoi consultare la cronologia delle versioni, confrontarle tra loro e ripristinare uno stato precedente quando necessario. Una sicurezza in più per lavorare in modo ordinato e senza rischi.
Piccola nota a margine come miglioramento prestazionale: nelle griglie di sola lettura il conteggio totale delle righe è nascosto per impostazione predefinita, ma può essere visualizzato tramite una nuova impostazione.

Process Modelling e Autoscale
Ecco la versione discorsiva anche per quest’ultimo blocco, in continuità con lo stile degli altri:
L’Autoscale ora gestisce gli start forms e il concatenamento delle attività e può eseguire più istanze dello stesso nodo (MNI). In pratica, i processi diventano molto più reattivi e scalabili, anche in scenari complessi o ad alto carico.
Dalla Dashboard degli Errori ora è possibile filtrare, riavviare o saltare migliaia di errori in un’unica operazione, rendendo la gestione delle eccezioni più agevole e meno manuale, soprattutto negli ambienti di produzione.
Bibliografia
https://docs.appian.com/suite/help/26.3/Appian_Release_Notes.html